Next Steps and Things to Try¶
Mastery of a new skill comes from practice and continued exploration. This final section provides a set of recommended exercises to solidify your understanding of the modeling workflow and introduces related topics for further independent study.
Recommended Practice Exercises¶
The following exercises are designed to build a more intuitive understanding of the concepts covered in this lesson. We recommend performing them in your lab notebook.
-
Analyze Hyperparameter Impact:
- The
max_depthhyperparameter directly controls the complexity of a Decision Tree. In our lab, we used a value of3. - Task: Re-run the workflow multiple times, using different values for
max_depth(e.g.,1,2,5,10, andNone). For each run, record both the accuracy on the training set and the accuracy on the test set. - Analysis: Observe the relationship between model complexity and performance. At what depth does the model begin to exhibit signs of overfitting (i.e., high training accuracy but declining or stagnant test accuracy)?
- The
-
Investigate Feature Importance:
- Our model used all four available features. However, not all features contribute equally to predictive power.
- Task: Train two new, separate models: one using only the
petal width (cm)andpetal length (cm)features, and another using only thesepal width (cm)andsepal length (cm)features. - Analysis: Quantify the performance difference between these two models. Which set of features appears to be more informative for this classification problem?
-
Evaluate the Impact of the Test/Train Split:
- The
test_sizeparameter in thetrain_test_splitfunction determines the allocation of data between training and testing. - Task: Modify the
test_sizeto0.5(50% for testing) and then to0.1(10% for testing). Re-run the workflow for each and observe the resulting test accuracy. - Analysis: Consider the trade-offs involved. A larger test set provides a more robust evaluation but leaves less data for model training. How might this choice impact your confidence in the model?
- The
-
Apply the Workflow to a New Dataset:
- The most effective way to confirm your understanding of the process is to apply it to a new problem.
- Task:
scikit-learnincludes a dataset on the chemical analysis of wines from three different cultivars (load_wine). Apply the complete end-to-end workflow to this dataset: load the data, prepareXandy, split, train aDecisionTreeClassifier, and evaluate its accuracy.
Topics for Further Exploration¶
For those who wish to look ahead, the following topics are logical extensions of this lesson. Understanding these concepts is fundamental to professional data science practice.
-
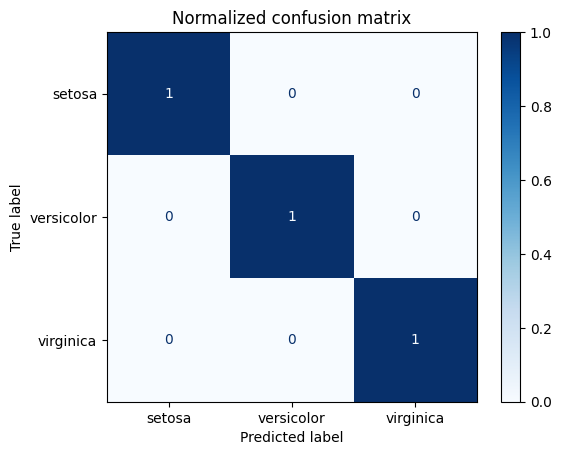
The Confusion Matrix:
- Accuracy provides a single, high-level score. A Confusion Matrix offers a more detailed breakdown of a classification model's performance, showing the number of true positives, true negatives, false positives, and false negatives. This is essential when the business costs of different types of errors are unequal.
Confusion Matrix Normalized Confusion Matrix 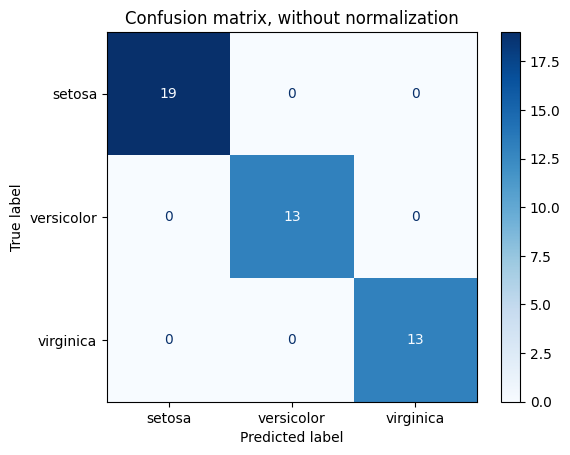
-
Precision, Recall, and F1-Score:
- Derived from the Confusion Matrix, these metrics provide more nuanced insights than accuracy alone. Precision measures the accuracy of positive predictions, while Recall measures the model's ability to identify all actual positive instances. They are critical for problems like disease detection or fraud analytics.
-
Alternative Classification Algorithms:
- The Decision Tree is just one approach. An alternative and highly intuitive method is K-Nearest Neighbors (KNN), which classifies a data point based on the majority class of its closest neighbors. Exploring other algorithms reinforces the concept that different problems may benefit from different tools.
-
Cross-Validation:
- A single train-test split provides one estimate of model performance, which can be subject to luck based on how the data was partitioned. Cross-Validation is a more robust evaluation technique where the splitting and training process is repeated multiple times to provide a more stable and reliable estimate of the model's performance on unseen data. This will be a core topic in our next lesson.