What is Cross-Validation? 🤔¶
In machine learning, you build a model to make predictions on new, unseen data. But how do you know how well your model will perform before you deploy it? You need to test it.
The simplest way is to split your data into two sets: one for training the model and one for testing it. This is a good start, but what if you were just unlucky with your split? Maybe the test set accidentally contained all the "easy" examples, making your model look better than it is. Or maybe it contained all the "hard" ones, making it look worse.
Cross-validation (CV) solves this problem. It's a technique where you systematically split the data into multiple training and testing sets to get a more reliable estimate of your model's performance. Instead of just one test score, you get several, which you can then average to get a more accurate and stable measure of how your model will generalize to new data.
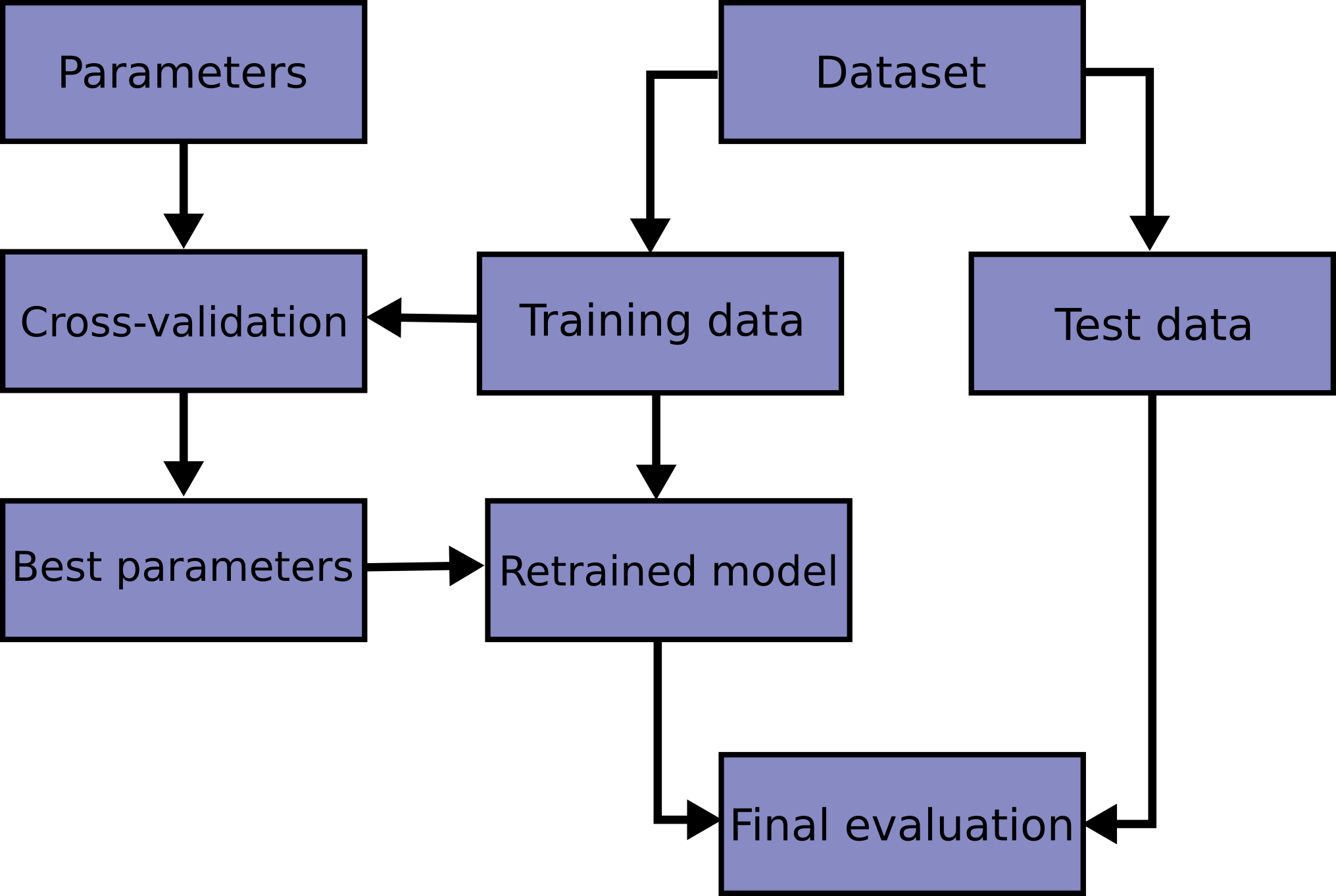 Image Credit: https://scikit-learn.org/
Image Credit: https://scikit-learn.org/
The Basic Split: train_test_split¶
This is the technique we previously introduced in our six-step workflow. This is just a starting point. While not technically a cross-validation method, it's the fundamental building block.
- How it works: It shuffles your dataset and splits it into two parts: a training set and a testing set. You decide the proportions, like 80% for training and 20% for testing.
- When to use it: Use this for a quick and simple model evaluation, especially with large datasets where the computational cost of running full cross-validation might be too high. It's a fast and easy way to get a first impression of your model.
Limitation: It only gives you one performance score. That score can be misleading if the random split isn't representative of the overall dataset.
from sklearn.model_selection import train_test_split
# X is your features, y is your target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Cross-Validation Techniques in Scikit-Learn¶
Now let's get into the actual cross-validation methods. These are more robust.
K-Fold¶
This is the most common and straightforward cross-validation technique.
-
How it works:
- It splits the dataset into 'k' equal-sized parts, or "folds" (e.g., k=5 or k=10).
- It uses one fold as the test set and the remaining k-1 folds as the training set.
- It repeats this process 'k' times, with each fold getting a turn to be the test set.
- You end up with 'k' different performance scores, which you can average to get a final, more reliable score.
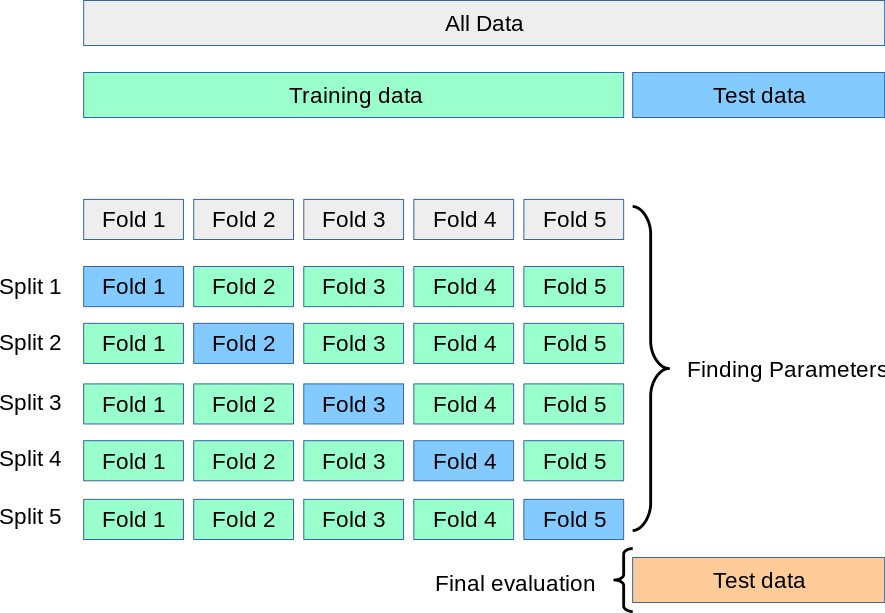 Image Credit: https://scikit-learn.org/
Image Credit: https://scikit-learn.org/
Cross validation using k-folds of training data. -
When to use it: K-Fold is a great default choice for cross-validation when you're working with a regression problem (predicting a number) or a balanced classification problem (where each class has a similar number of samples).
Stratified K-Fold¶
This is an improved version of K-Fold specifically for classification problems where the classes are imbalanced.
- How it works: It does the same thing as K-Fold but with one crucial difference: when making the folds, it ensures that each fold has roughly the same percentage of samples from each class as the original dataset. For example, if your dataset is 80% Class A and 20% Class B, Stratified K-Fold makes sure every fold has that same 80/20 split.
-
Why that matters: This prevents a situation where, by pure chance, one of your folds ends up with very few or zero samples from a minority class, which would make the model's evaluation for that fold meaningless.
-
When to use it: Always use Stratified K-Fold for classification problems, especially when your classes are imbalanced. It's generally a safer and more reliable choice than standard K-Fold for classification.
Group K-Fold¶
This is a specialized version for when your data has "groups" or "clusters."
- How it works: In some datasets, data points are not independent. For example, you might have multiple medical readings from the same patient, or multiple product reviews from the same user. If you use regular K-Fold, you might end up with data from the same patient in both the training and testing sets. This is bad because the model might learn to recognize the specific patient rather than the general medical condition, a form of "data leakage." Group K-Fold ensures that all the data from a single group (e.g., one patient) will be in either the training set or the test set, but never both.
- When to use it: Use Group K-Fold when you have groups of related or non-independent data points. Common examples include repeated measurements on the same subject, medical data from multiple patients, or reviews from the same users.
Stratified Group K-Fold¶
As the name suggests, this method combines the features of Stratified K-Fold and Group K-Fold.
- How it works: It keeps groups intact (like Group K-Fold) while also preserving the class balance within each fold as best as possible (like Stratified K-Fold).
- When to use it: Use Stratified Group K-Fold when you have both grouped data and an imbalanced class distribution. This is common in medical diagnoses (multiple patients with an imbalanced disease rate) or user-based classification problems where the outcome is imbalanced.
Putting It Into Practice ⚡¶
While it's important to understand how KFold and StratifiedKFold work under the hood, you will rarely instantiate them manually in your day-to-day work.
Scikit-learn has convenient high-level functions that perform the entire cross-validation loop for you. The best part? They automatically choose the right kind of cross-validation for you!
- If you give them a classifier, they will use
StratifiedKFoldby default. - If you give them a regressor, they will use
KFoldby default.
This helps prevent common mistakes and makes your code much cleaner.
The Easy Way: cross_val_score¶
Let's look at the most common way to run a cross-validation using cross_val_score(). This function fits and evaluates a model on all the folds and returns the list of scores.
Notice how much simpler the code is. By just setting cv=5, we are telling scikit-learn to perform a 5-fold cross-validation. Because we are using a classifier (LogisticRegression), it automatically uses stratification.
import numpy as np
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import make_classification
# --- 1. Setup: Create a sample imbalanced dataset and a model ---
# X = features, y = target labels
X, y = make_classification(n_samples=100, n_features=20,
n_informative=2, n_redundant=10,
weights=[0.9, 0.1], # Imbalanced classes (90% vs 10%)
flip_y=0, random_state=42)
# Create a logistic regression model
model = LogisticRegression()
# --- 2. The Easy Way: Let scikit-learn do the work ---
# By passing cv=5 to a classifier, scikit-learn automatically uses StratifiedKFold
# to ensure class balance is preserved in each fold.
scores = cross_val_score(model, X, y, cv=5, scoring='accuracy')
# --- 3. Review the results ---
print(f"Scores for each of the 5 folds: {np.round(scores, 2)}")
print(f"Average CV Accuracy: {scores.mean():.2f} (+/- {scores.std():.2f})")
# Expected Output:
# Scores for each of the 5 folds: [0.9 0.9 0.9 0.95 0.85]
# Average CV Accuracy: 0.90 (+/- 0.03)
When Would You Manually Create a KFold Object?¶
You only need to manually create a cross-validation object when you need specific control that the default behavior doesn't offer. For example:
- Forcing a shuffle: To shuffle the data before splitting, you need to create an object. This is good practice.
- Reproducibility: To get the same folds every time you run your code, you must set a
random_state. - Using Groups: When you need to use
GroupKFoldorStratifiedGroupKFold, you must instantiate them and pass the object to thecvparameter.
Here is how you would do that:
from sklearn.model_selection import StratifiedKFold, cross_val_score
# I want to control the shuffling and ensure my results are reproducible
# so I create a StratifiedKFold object.
custom_cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
# Now, I pass this object to the cv parameter
scores = cross_val_score(model, X, y, cv=custom_cv)
print(f"Scores from custom CV object: {np.round(scores, 2)}")
print(f"Average CV Accuracy: {scores.mean():.2f}")
In summary: Start by simply using an integer for the cv parameter (e.g., cv=5). Only create a full KFold or StratifiedKFold object when you have a specific reason to, like needing to set a random_state or use groups.
Summary: Which One Should I Use?¶
| Method | When to Use It | Key Idea |
|---|---|---|
train_test_split |
For a quick, preliminary check, especially with very large data. | A single, simple split. |
KFold |
The go-to for regression problems. Also fine for balanced classification. | Splits data into 'k' folds, rotating which fold is the test set. |
StratifiedKFold |
The default choice for classification problems, especially with imbalanced classes. 🏆 | Same as K-Fold, but keeps class proportions the same in each fold. |
GroupKFold |
When your data has groups (e.g., multiple samples from the same patient or user). | Ensures that all data from a group is in either training or testing, not both. |
StratifiedGroupKFold |
When you have both grouped data and imbalanced classes. | A combination of stratified and group logic. |